YouTube-8M Segments Dataset
The YouTube-8M Segments dataset is an extension of the YouTube-8M dataset with human-verified
segment annotations. In addition to annotating videos, we would like to
temporally localize the entities in the videos, i.e., find out when the entities occur.
We collected human-verified labels on about 237K segments on 1000 classes from the validation set
of the YouTube-8M dataset. Each video will again come with time-localized frame-level features
so classifier predictions can be made at segment-level granularity. We encourage researchers to
leverage the large amount of noisy video-level labels in the training set to train models for
temporal localization.
We are organizing a
Kaggle
Challenge and
The 3rd
Workshop on YouTube-8M Large-Scale Video Understanding at
ICCV 2019.
237K
Human-verified Segment Labels
|
1000
Classes
|
5.0
Avg. Segments / Video
|
Dataset Vocabulary
The vocabulary of the segment-level dataset is a subset of the YouTube-8M dataset (2018 version)
vocabulary. We exclude the
entities that are not temporally localizable like movies or TV series, which usually occurs in the whole video.
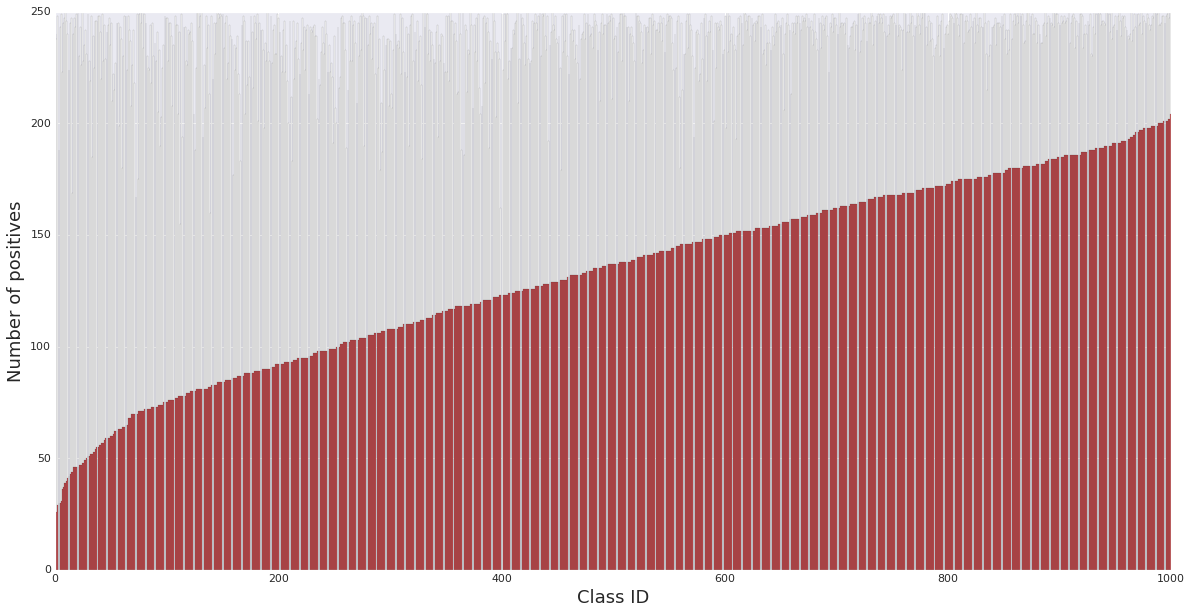
The following figure shows the distribution of the ratings in the YouTube-8M Segments dataset.
Each class contains up to 250 human ratings (indicated by the grey bar in the background).
The number of positives (indicated by the red bar) varies between classes.
YouTube-8M Dataset
YouTube-8M is a large-scale labeled video dataset that consists of millions of YouTube video IDs, with
high-quality machine-generated annotations from a diverse vocabulary of 3,800+ visual entities. It comes with precomputed
audio-visual features from billions of frames and audio segments, designed to fit on a single hard disk. This
makes it possible to train a strong baseline model on this dataset in less than a day
on a single GPU! At the same time, the dataset's scale and diversity can enable deep exploration of
complex audio-visual models that can take weeks to train even in a distributed fashion.
Our goal is to accelerate research on large-scale video understanding, representation
learning, noisy data modeling, transfer learning, and domain adaptation approaches for video.
More details about the dataset and initial experiments can be found in our
technical report
and in previous workshop pages (
2018,
2017).
Some statistics from the latest version of the dataset are included below.
6.1 Million
Video IDs
|
350,000
Hours of Video
|
2.6 Billion
Audio/Visual Features
|
3862
Classes
|
3.0
Avg. Labels / Video
|
Dataset Vocabulary
The (multiple) labels per video are
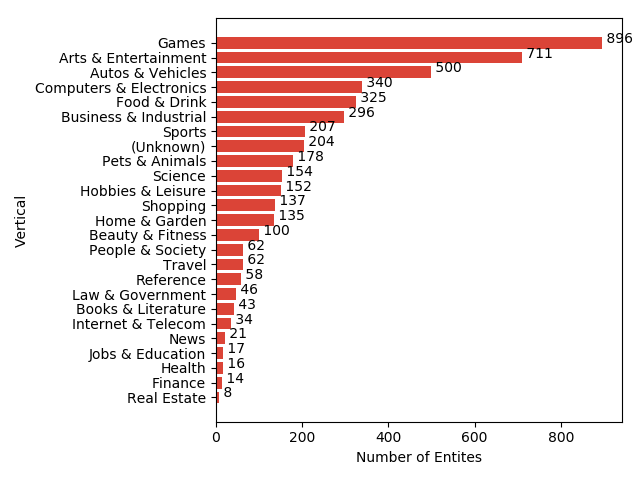
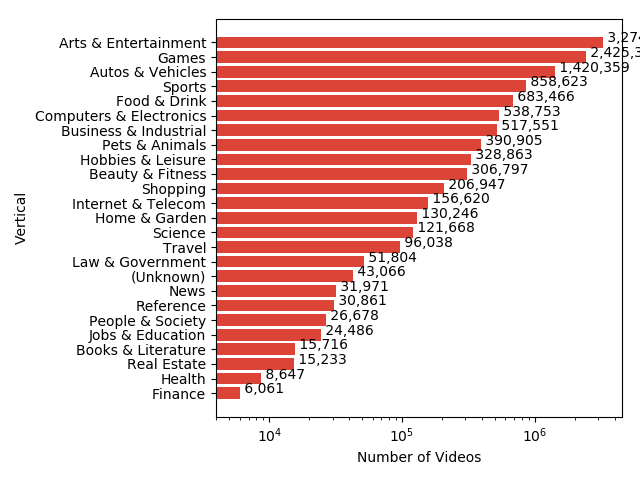
Knowledge Graph entities, organized into 24 top-level verticals.
Each entity represents a semantic topic that is visually recognizable in video, and the video labels reflect the main topics of each video.
You can download a
CSV file (2017 version
CSV, deprecated) of our vocabulary.
The first field in the file corresponds to each label's index in the
dataset files,
with the first label corresponding to index 0. The CSV file contains the following columns:
Index,TrainVideoCount,KnowledgeGraphId,Name,WikiUrl,
Vertical1,Vertical2,Vertical3,WikiDescription
The entity frequencies are plotted below in log-log scale, which shows a Zipf-like distribution:

In addition, we show histograms with the number of entities and number of training videos in each top-level vertical:
People
This dataset is brought to you from the Video Understanding group within
Google Research. More
about us.
If you want to stay up-to-date about this dataset,
please subscribe to our
Google Group: youtube8m-users.
The group should be used for discussions about the dataset and the starter code.