The Rule Reranker
The Rule Reranker is an advanced feature of the Semantic Reactor that allows you to tweak the default behavior of the models by applying a set of rules. When the conditions specified in a rule are satisfied in a particular candidate, then the score for that candidate adjusts and the full list of candidates is resorted.

Rules operate under a simple condition: “If the user input is similar to the Target Input and the candidate is similar to the Target Response, then boost the candidate’s score.”
Each rule is made up of five parts and each rule is applied to every candidate.
- Target Input is text that the user’s input will be compared against.
- Input Similarity Minimum is the lowest semantic similarity score comparing Target Input and the user’s input must exceed in order for the rule to have an effect.
- Target Response is text that the candidates will be compared against.
- Response Similarity Minimum is the lowest semantic similarity score comparing Target Response and the candidate must exceed in order for the rule to have an effect on that candidate.
- Rule Boost determines the potency of the rule and whether it is positively or negatively influencing the score.
The rule’s potency is affected by the similarity of the input and response matches. If both are near perfect matches to the target, then the rule will change the candidate’s score by nearly the full rule boost. If either are just barely above their similarity minimum, then the rule will apply a much smaller change to the candidate’s score.
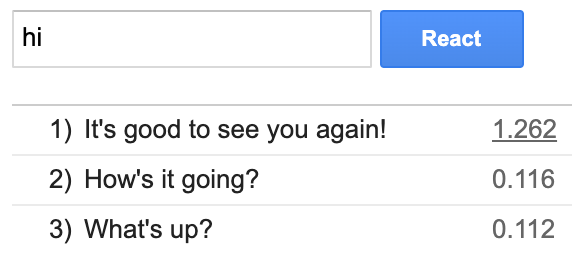
When a rule is applied, the score appears underlined in the results table. Click on the score to see a breakdown of the rule’s effect.
Any candidate list can have rules attached to it. Simply add another sheet (tab) and give it the same name as your candidate list but with “.rules” appended to it. Then make sure the “...with Reranker” option is selected, reload, and click “React” to see the effect. Note: the first line of the rules file is treated as a header row and has no effect on the sort.
Here is a sheet you can experiment with.
Tips
- Rule Boosts can be positive or negative. Use this to encourage or discourage responses from the model.
- If the rule isn’t triggering, reduce the Input or Response Similarity Minimum. If the rule is triggering too often, increase it.
- Try thinking of each rule as a soft brush that gently adjusts the model behavior. Higher similarity minimum values give your brush a finer and more precise tip. Increasing the Rule Boost makes the rule act with heavier brush strokes.
Formula
The rules system works by giving example input / response pairs and specifying how similar results should be biased.
The rule inputs are compared to the user’s input with the Semantic Matcher. Any rules which satisfy the Input Similarity Minimum (i.e. the rule’s input and user’s input have a semantic match score above that threshold) will then move on to the response matching phase.
Similar to the input phase, the rule’s response field will be semantically matched against all the candidates in the sheet’s default tab. All candidates that semantically match above that response similarity minimum will have a bias added.
The bias is calculated by multiplying three values:
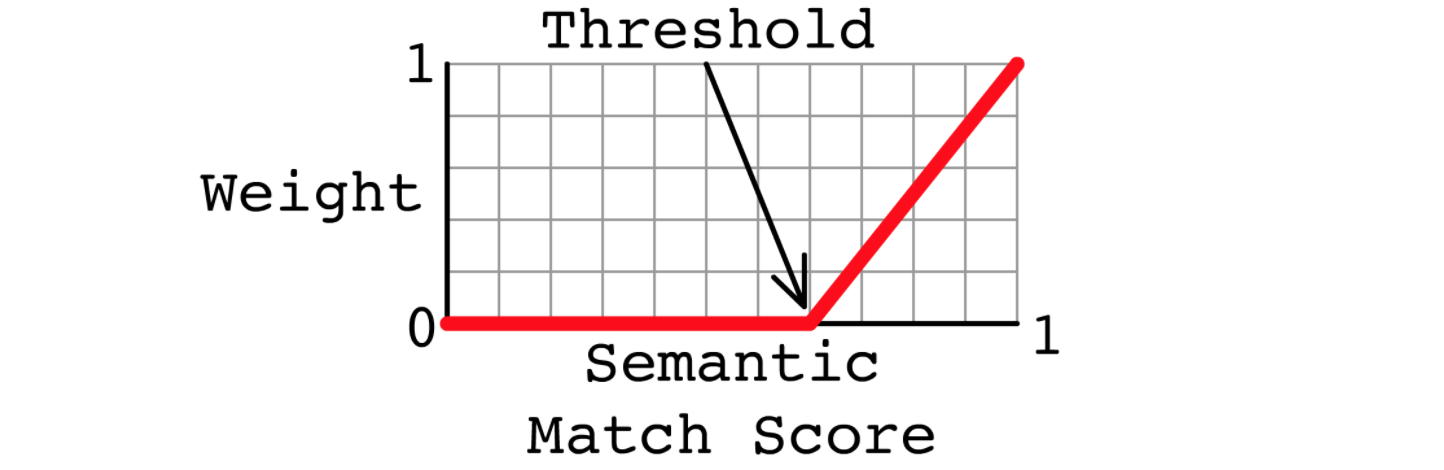
Input weight is a (0, 1] value calculated with the formula:
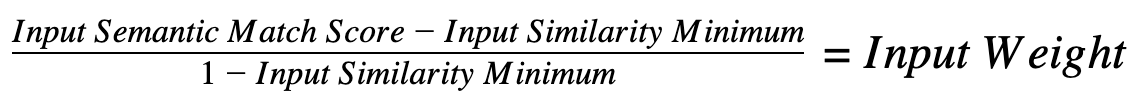
Similarly, the response weight is a (0,1] value calculated with the formula:
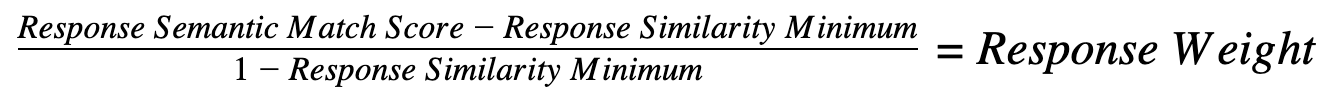
Input weight and response weight are visualized with this graph:
Rule boost is the final field specified in the rules sheet.
Once the three values are multiplied together, this rule bias is added into the candidate’s bias.